
The possibility to model a glotal chink is also important to simulate
fricatives, and especially voiced fricatives [1]. Indeed, voiced fricatives
require both a voiced source, generated by the oscillating vocal folds,
and a sufficiently large volume velocity through the supraglottal
constriction to generate the frication noise. Without glottal chink,
the second condition may not be satisfied due to the absence of the DC
component in the glottal flow waveform. The influence of the glottal
chink in the production of voiced fricative is highlighted in the following figure:
the larger the chink, the higher the frication noise level.
Interestingly, a very large opening of the chink may lead to a
predominant frication noise in comparison with the voiced source, and,
therefore, may lead to a devoicing of the fricative. In this example,
the voiced fricative /z/ is devoiced when the glottal chink is too
large (right column), and souds like a /s/.
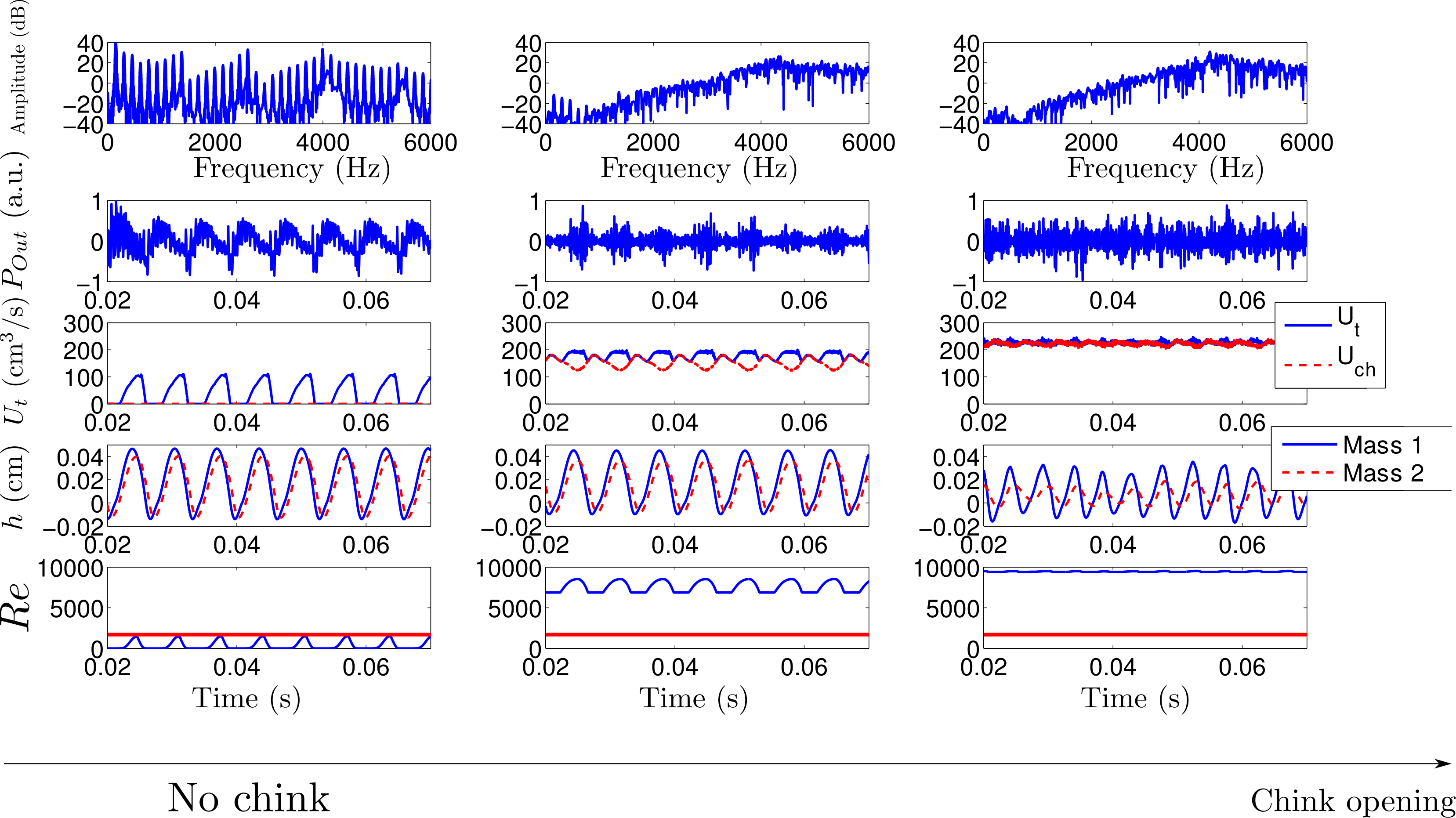
Simulations of a sustained /z/
with different chink length: (left) closed chink, (center) lg=0.3cm,
(right) lg=0.5cm$. From top to bottom :
spectrum, output acoustic pressure, glottal flow (solid blue line) and
chink flow (dashed red line), position of the masses, and Reynolds
number (solid blue line). The horizontal red line in the bottom plot is
the threshold above which the frication noise is generated.
References :
[1] Elie B. and Laprie Y. (2017), Acoustic impact of the gradual glottal abduction on the production of fricatives: A numerical study– Journal of the Acoustical Society of America 142, 3, pp. 1303–1317.




